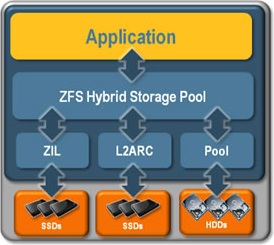
RADZ2 je alternativa Linux RAID6. Na checksum jsou tedy použity dva disky. Nejmenší počet disků, pro které lze tuto konfiguraci použít jsou 4. V takovém případě ale počítejte s tím, že pole bude mít jen poloviční kapacitu součtu kapacit disků.
Další problém pouze 4 disků (pokud ke stroji nemůžete dočasně připojit další) je ten, že SmartOS při instalaci RAIDZ2 pole vytvořit neumí. A když systém nainstalujete jen na jeden disk, ze zbylých 3 disků RAIDZ2 pole nevytvoříte. Jeden disk vám bude chybět. Jak tento nedostatek obejít?
Začneme instalací. Nejprve si systém nainstalujeme pouze na jeden disk.

Když máme instalaci hotovou, nabootujeme SmartOS bez importu zfs poolů.

Importujeme pool zones pod názvem zones2

Odmountujeme dataset zones2/cores.
umount zones2/cores
Smažeme složku /zones, aby nepřekážela až budeme vytvářet pool zones.
rm -r /zones
Zjistíme, kolik zabírá celý pool zones2.

Vytvoříme pomocí dd prázný sparse soubor větší než velikost poolu zones2.

Vytvoříme RADZ2 pole ze zbylých 3 disků a soubor z předešlého kroku použijeme jaho čtvrtý disk. Parametr -f je nutný aby příkaz zpool neřval kvůli rozdílným velikostem disků a že mixujeme jednotky a soubory.

Soubor použitý u poolu jako jeden z disků převedeme do offline stavu. Tento krok je důležitý. Bez něj by při přenášení dat mezi pooly došlo na SmartOS ramdisku místo.

Volitelně můžeme před přenosem zapnout kompresi disku. Soubory se nám pak během přenosu budou ukládat zkomprimované.
zfs set compression=gzip-9 zones2
Vytvoříme rekurzivní snapshot poolu zones2.

Přemigrujeme data z poolu zones2 do zones. Přepínač -R u zfs send říká, že pošleme rekurzivně i podřízené datasety. Přepínač -p posílá i properties datasetů (např. nastavenou kompresi). Přepínač -F u zfs recv zajistí, že se v cílovém poolu promaže vše, co tam nemá být.

Smažeme snapshot current v cílovém poolu
zfs destroy -r zones@current
Pokud vše proběhlo v pořádku, můžeme nyní zrušit pool zones2
zpool destroy zones2
Nahradíme soubor použitý při vytváření poolu zones diskem, který se nám nyní uvolnil

Po chvíli máme data sesynchronizována a pool zones už jede na plnohodnotném RAIDZ2 poli.

Nyní je ještě potřeba pool rozšířit na celou kapacitu disků.

Projistotu provedeme export poolu.
zpool export zones
A uděláme reboot. Po najetí SmartOS s importem poolů vše pojede z právě vytvořeného RAIDZ2 pole. Enjoy!